

Ao implantar uma ditadura em 1930, Getúlio Vargas modernizou o Brasil, que se tornou um Estado autoritário e centralizado na figura do presidente. O “Pai dos Pobres”, como também é conhecido, é responsável pela Consolidação das Leis Trabalhistas (CLT), pela criação do BNDE (atual BNDES), a fundação e o desenvolvimento da Petrobrás, e também pela inserção do Brasil na Segunda Guerra Mundial.
O icônico presidente brasileiro chegara ao poder, como chefe do governo provisório, em 1930, marcando o fim da República Velha, e fica no poder até 1945, elegendo-se novamente em 1951 como Presidente da República, cargo que ocupou até 1954. Vargas cometeu suicídio em 24 de agosto de 1954, no Palácio do Catete, no antigo Distrito Federal, no Rio de Janeiro e era conhecido pela sua eloquência e por seus discursos, considerados grandes ensinamentos políticos.
Por esse motivo, me proponho a analisar alguns discursos de Vargas na presidência. Especificamente, analisarei todos os discursos proferidos entre 1930 e 1937, 1939, 1941, 1944 e o discurso de posse de 1951. Para isso, utilizarei o pacote quanteda para o R, além do tidyverse. Os discursos podem ser obtidos aqui, no site da Biblioteca da Presidência.
O primeiro passo é carregar os pacotes que serão de fato utilizados, com o pacman:


Em seguida, vamos abrir os discursos. A função readtext permite importar as mais diversas extensões de texto de uma só vez, permitindo a criação de um corpus rapidamente.


O argumento docvarnames utiliza o nome do arquivo para adicionar variáveis ao banco. Como estruturei os discursos da seguinte maneira: ANO_ORDEM.pdf, utilizando o separador _, crio as variáveisano e ordem, representando o ano em que o discurso foi proferido e em qual posição ele está (naquele ano).
Isso fica bem claro abaixo:
head(vargas, 6)
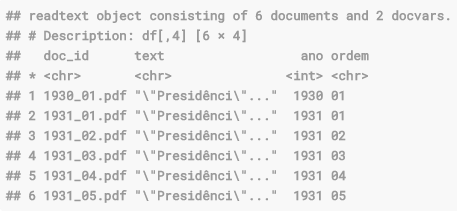

Temos um banco com documentos em pdf que guardam o discurso, o ano e a ordem do mesmo. Todavia, ele ainda não está em um formato próprio para nossa análise, devendo estar dentro do formato corpus.
Além disso, nosso arquivo em PDF guarda um problema comum à todos os PDFs: a hifenização. Um PDF é um arquivo pronto para imprimir, então o texto que está nele, quando selecionado, pode vir com alguns erros. O erro mais comum e que já corrigiremos prontamente é o da hifenização.
Supondo que em nossos arquivos exista a palavra república. Em alguns momentos, essa palavra se encontra no fim da linha e não cabe na mesma. Por conta disso, ela é hifenizada, continuando na linha seguinte. Quando transposta para nosso banco de dados, é possível que apareçam as variações re- pública, repú- blica, repúbli- ca. Tudo isso será entendido pelo software como palavras diferentes, quando no fundo, são a mesma.
Logo, antes de transformar em corpus, que é o conjunto de textos que iremos analisar, vamos corrigir esse erro usando o str_replace_all com regex. Em seguida, transformamos em corpus:

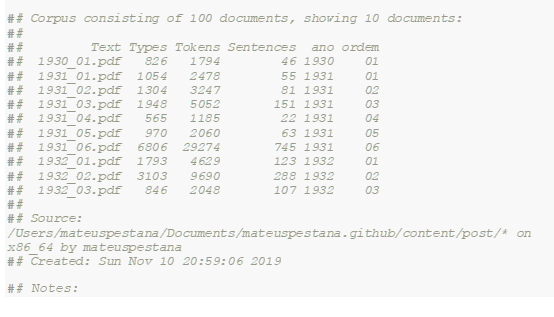

A saída do comando summary em um objeto de corpus apresenta os textos, a quantidade de caracteres (types),a quantidade de tokens e o número de frases de cada documento, além das variáveis que escolhemos anteriormente.
Agora, para fazermos uma análise de frequência de palavras, por exemplo, precisamos dividir nosso corpus em unidades, denominadas tokens, que podem ser caracteres, palavras, sentenças, parágrafos.
Nesse caso, o ideal para a análise que desejo fazer é dividir em palavras, ou n-gramas, pegando cada palavra individualmente. Retirarei pontos, números, separadores, símbolos e hífens. Depois disso, removerei palavras que nada representam e não auxiliam, denominadas stopwords, do pacote de mesmo nome: artigos, preposições, alguns verbos, etc.
Além disso, removerei outras palavras, como art (de artigo, quando Vargas cita leis), à, às, é, assim, sobre, ainda, e algumas frases que pertencem ao cabeçalho do arquivo. Há também um problema, que às vezes a palavra república aparece como repdblica, um erro no OCR. Isso será corrigido.

Com isso, já podemos fazer uma análise da frequência de palavras nos discursos de Getúlio Vargas, podendo descobrir assim as palavras mais utilizadas por ele, dando uma pista sobre temas, termos e o que realmente era relevante (pelo uso). Antes de fazer a frequência, precisamos converter os tokens em uma document-feature matrix, que nada mais é que uma matriz de frequência de termos em documentos:


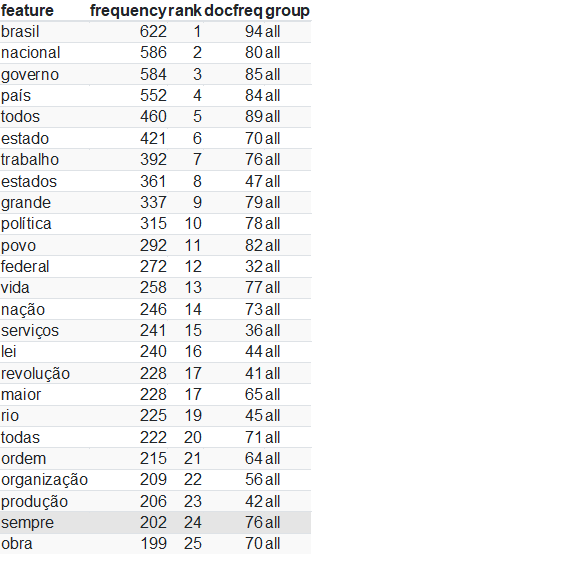

Percebemos que, no nosso corpus, a palavra Brasil aparece 622 vezes em 94 dos 100 discursos. Depois dela, Nacional é utilizada 586 vezes, aparecendo em 80 documentos. Povo aparece na 11ª posição, sendo utilizada 292 vezes, aparecendo em 82 discursos, o que faz todo o sentido, a partir do que se sabe sobre Vargas.
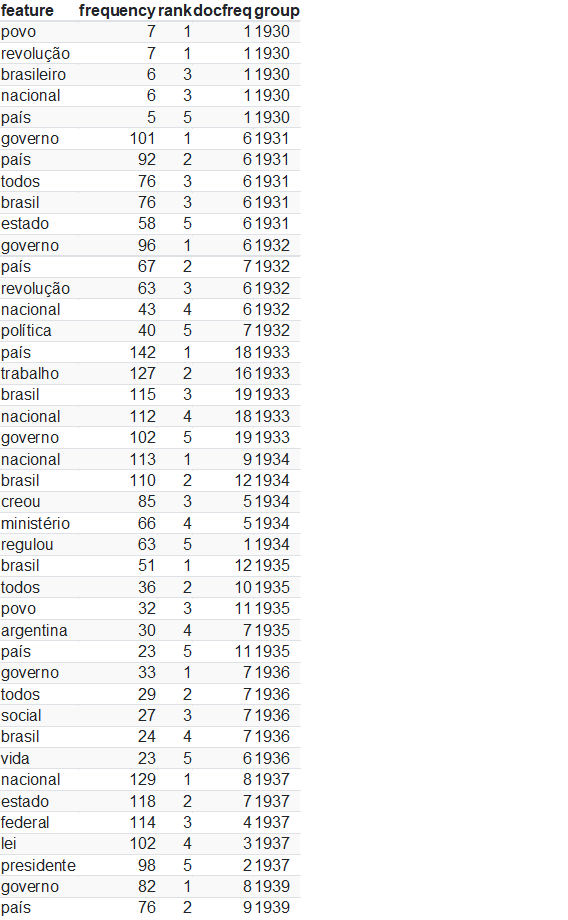
Podemos fazer a mesma análise de frequência de palavras agrupando por ano, e pegando as 5 palavras mais usadas em cada ano:



Fazendo uma nuvem de palavras (wordcloud) dos 200 termos mais utilizados por Vargas, temos:
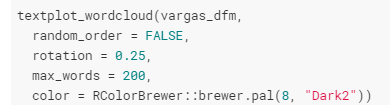



A nuvem de palavras é simplesmente um recurso gráfico da tabela de frequência de palavras: o tamanho da palavra indica a quantidade de vezes que ela é utilizada, e é proporcional às outras ali presentes.
O Estado Novo inicia em 1937, com o fim do Governo Constitucionalista (1934-1937), e vai até 1945. Será que houve alguma mudança nas palavras utilizadas por Vargas no primeiro ano de cada período de governo, ou seja, em 1931, 1934 e 1937?
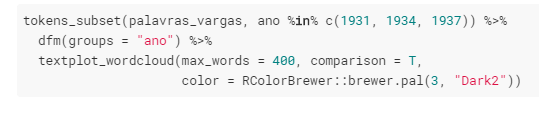

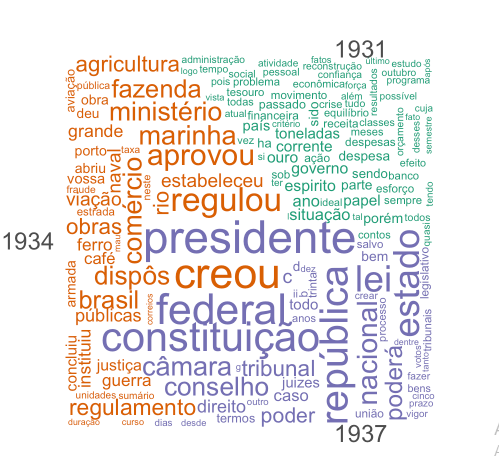

O que percebemos acima é que Vargas varia um pouco nas palavras utilizadas nos primeiros anos de seus governos: em 1931, percebemos o uso de palavras como governo, toneladas, papel, ouro, despesa, econômica, classes, tesouro; já em 1934, com o início do Governo Constitucionalista e promulgação da Constituição de 1934, palavras como fazenda, ministério, comércio, marinha, brasil, obras, públicas, cinema, saúde, ferro, café, naval se fazem presentes; em 1937, durante o Estado Novo, Vargas utilizou mais as palavras presidente, federal, lei, constituição, república, estado, nacional, segurança, câmara, tribunal, poder.
O quanteda é excelente pois traz consigo um conjunto de funções facilitadas, tornando muito mais fácil o cálculo de algumas estatísticas e a plotagem de alguns gráficos. Um outro exemplo é o gráfico de co-ocorrência, em rede, que indica quais palavras costumam ocorrer no mesmo documento, ou na mesma frase, a depender de como se configura. Ao analisarmos a co-ocorrência de palavras nos discursos de Vargas, temos, através da função textplot_network:


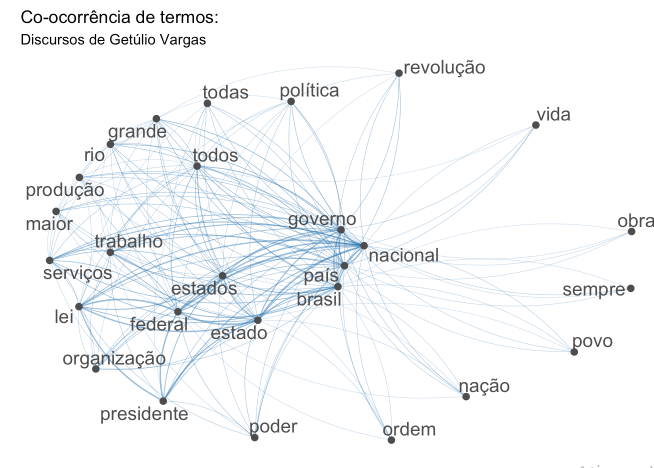

O gráfico acima nos permite perceber que, por exemplo, país, governo, nacional, brasil,e stado, federal, todos são palavras com um alto grau de co-ocorrência com todas as outras. Talvez seja mais interessante observar as palavras que não co-ocorrem entre si: povo e nação, por exemplo, ou poder, povo, ordem e obra.
Um outro exemplo interessante de análise é a presença de determinado termo ou termos ao longo do documento, e em que posição aparecem. Isso é oferecido pela função textplot_xray. Observando em quais discursos a palavra democracia (ou democratas, democrata, democrático, democrática, etc) aparece, e em que posições do documento:

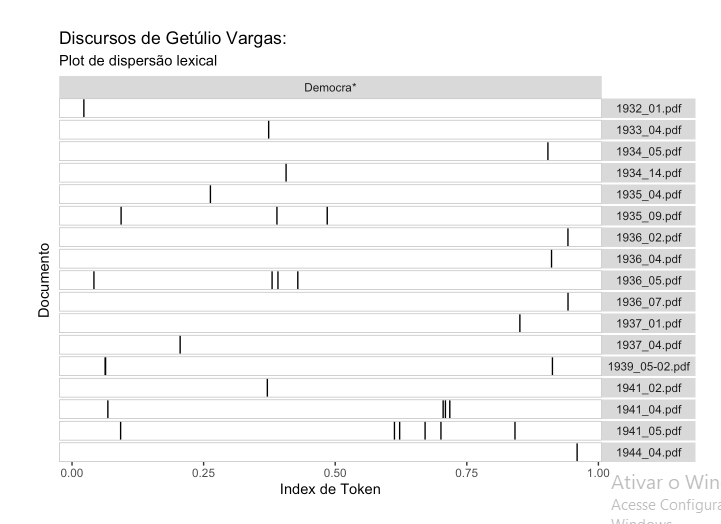

Democracia só aparece em 1 discurso em 1932, em 1 em 1933, em 2 em 1934, em 2 em 1935, em 4 em 1936, em 2 em 1937, em 1 em 1939, em 3 em 1941 e em 1 em 1944, de um total de 100 discursos existentes.
Mas qual seria o contexto da palavra nos discursos?
kwic(discursos_vargas, "Democra*", window = 3)


Percebe-se que a palavra democracia, em muitos dos casos acima, é utilizada em um contexto negativo.
Uma ferramenta muito útil é a de topic modeling, que permite o cálculo de termos relacionados que possam indicar um assunto em comum, ou tópicos. Será que é possível identificar tópicos recorrentes nos discursos de Getúlio Vargas?
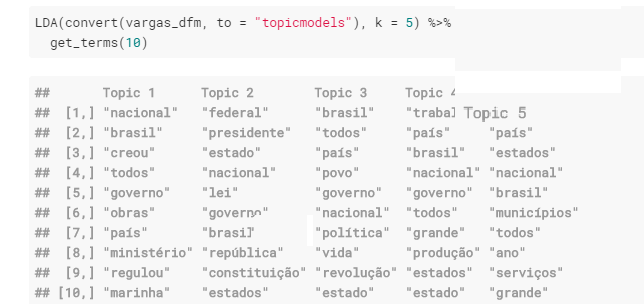

Calculei 5 tópicos possíveis nos discursos de Vargas e, de cada um, selecionei as 10 palavras que pudessem representar cada tópico. Por conta de todos os discursos versarem, na maioria das vezes, sobre as mesmas coisas, com uma grande quantidade de palavras repetidas, fica difícil identificar tópicos diferentes. Todavia, se ignorarmos as palavras repetidas e focarmos nas únicas, podemos perceber alguns temas: estado e social, lei e presidente, nação e revolução, obras e serviços, povo e trabalho.
Por fim, o quanteda também apresenta a ferramenta de collocations, que é o cálculo de palavras que sempre andam juntas, em bi-gramas (ou seja, pares). Quais serão os termos correlacionados nos discursos de Getúlio? Para essa análise, precisamos fazer novamente os tokens adicionando a opção de padding = TRUE, para que os espaços vazios (de palavras removidas, como stopwords) não sejam ocupados pelas palavras seguintes.

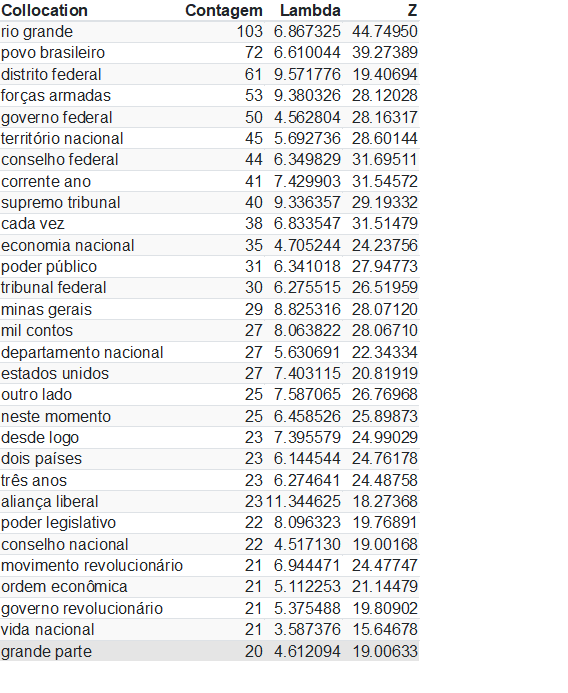

Rio Grande, Povo Brasileiro, Distrito Federal e Forças Armadas são os bigramas mais utilizados por Getúlio Vargas. O primeiro é óbvio: se refere ao Rio Grande do Sul, terra de Getúlio Vargas; Povo Brasileiro era como ele iniciava os discursos, se dirigindo à nação; Distrito Federal se refere à capital; Forças Armadas mostra as relações de Getúlio com os militares, fruto da própria Revolução de 30.
Bom, por hoje é só! Quero agradecer aos insights dos amigos Helio Cannone e Weslley Dias, que possuem relevantes pesquisas sobre Vargas e entendem profundamente do assunto.




